At the end of November last year, JIDOKA organised a hackathon from Friday evening after work until Sunday in the late afternoon. Together with 2 colleagues I formed 1 of the 7 teams that participated. The subject that we chose is something that almost every developer in the world has some sort of problem with: timesheets.

I think we can all agree that no sane person on this earth likes to fill in timesheets, but that they are a necessary evil. As long as there’s only one timesheet system to use and you only have a small number of tasks to book time on it is mostly manageable. But when there are multiple timesheet systems or when you have a lot of different tasks to log time on it quickly becomes a problem to keep up with logging your time correctly and on time and to keep the systems in sync.
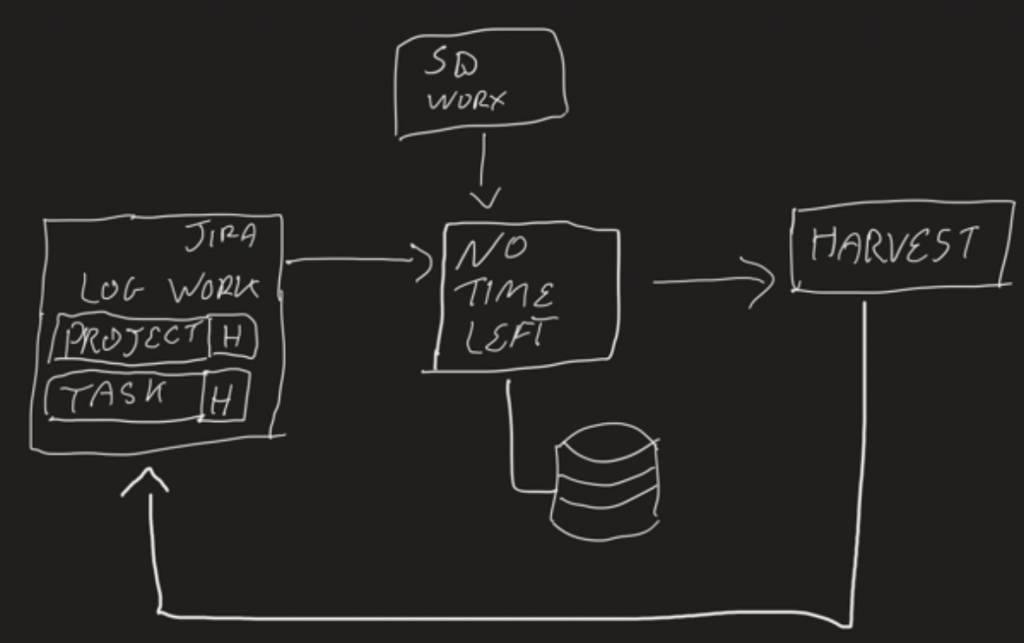
In the case of JIDOKA, there are 2 timesheet systems: Atlassian Jira (with the Tempo plugin) and Harvest.

The first one, Jira, is used for project management and contains the projects/tickets we’re working on as developers. We log all the time we spent on a certain ticket and the Tempo plugin combines all these worklogs into an employee timesheet that can be submitted monthly. This system is mostly used by the development team to track what work was done on a project and by whom, and to report on project progress.
The second system, Harvest, is mainly used by project managers, the management team and the finance department, to track project budgets and send out invoices.
Both systems basically track time, but in a different way, with a different granularity and both need to kept in sync by the user creating the worklogs. This causes a bunch of problems:
- ticket/project/task on one or both sides does not exists
- user does not have access to ticket/project/task on one or both sides
- easy to make mistakes while mapping the time logged in one onto the other system
- no good correlation between systems
- …
The end result is that there is a lot of friction, timesheets aren’t completed in time, timesheets are out of sync and developers are questioning the meaning of life and whether estimates or timesheets are the thing they hate the most about their job.

Goal
So our team decided to try and do something about it. We set a goal to try to improve the system in such a way that developers would only have to log time in one system and that the other system would be kept in sync automatically. We are IT professionals after all and automating mundane tasks is what we live for. With such a system in place we could keep both management/finance and our developers happy. Enter: No Time Left! (what’s in a name)

Team and methodology
Our team consisted of 3 people:
- 2 developers (myself included) of which 1 with an affinity for frontend development and the other one for backend development
- 1 analyst/PM (props to him being at a hackathon!)
The first day, or better evening, was a Friday after work where we first had to drive to the location the hackathon was being held. This meant we only had a couple of hours before we needed some sleep. Because our analyst/PM had just returned from an “Agile Project Management” course, we decided to try and apply what he had learned.
So we spent the next couple of hours doing a bunch of tasks:
- Defining what the exact problem was we wanted to solve
- Defining the different ways that could be used to solve the problem
- Doing some quick research & POCs to evaluate/rate these solutions
- Here we quickly checked what existing applications/plugins/APIs existed that could help us
- Based on this information decide which solution to implement
- Draw up an action plan and divide the work
In the end we settled on the following approach:
- Extend the Jira ticket interface so that the person that creates the tickets can easily link them to a Harvest project task.
- Create central component that can gather worklogs from multiple sources (Jira would be one) and that will propagate changes (create/update/delete) to multiple target systems (of which Harvest would be one)
Technology and solution
Due to the limited length of the hackathon we decided to keep things simple and to stay close to the technology stack that Jidoka uses internally. We also took a couple of shortcuts, such as not creating a frontend for the central component and using a fixed user mapping between the source and target system.
For the Jira side we settled on using the excellent Elements Connect plugin. This plugin allows us to use the Harvest v2 REST API to define a datasource that we could then use to create 2 linked custom fields that would be filled with all available projects and their tasks. These 2 custom fields can then be configured in Jira to appear on every ticket so that a project manager can define on a ticket-by-ticket basis where the time would get synced to in Harvest.
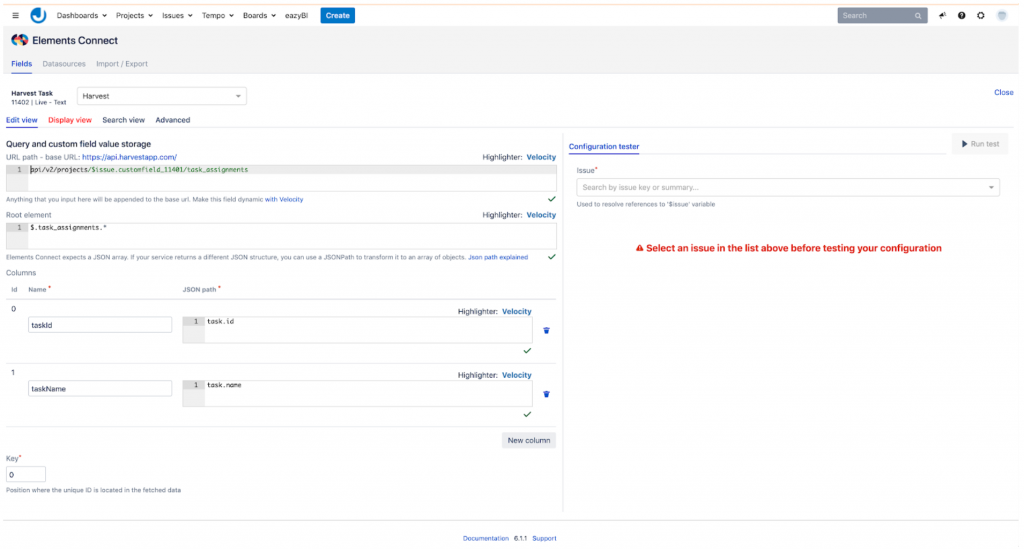
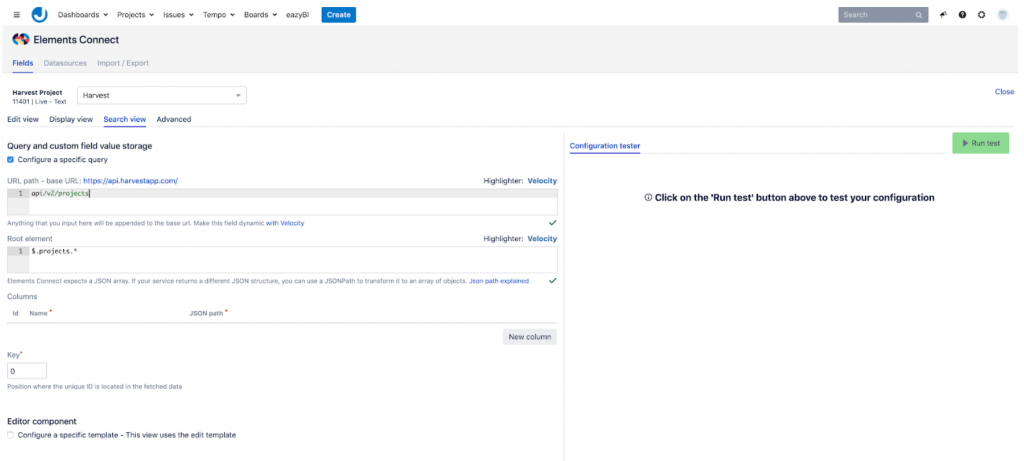
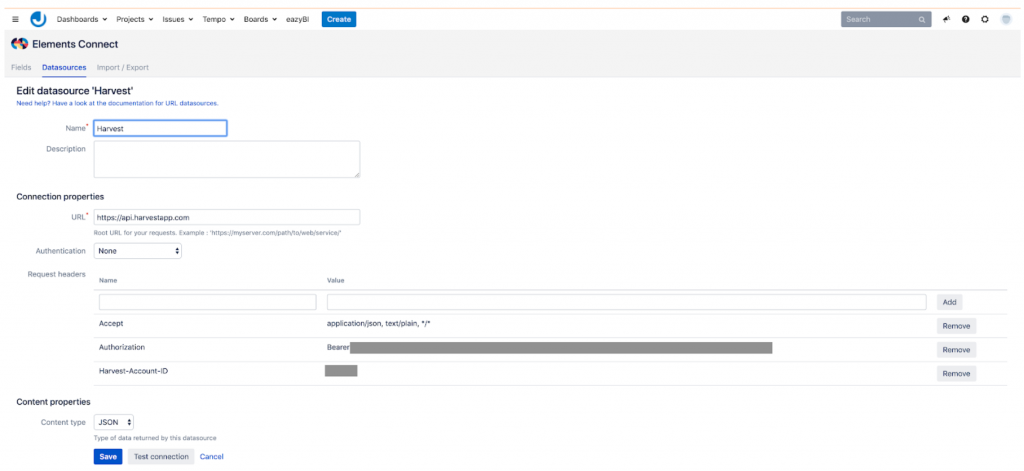
For the Time sync component we defaulted to Spring Boot 2.x and used OpenFeign to be able to quickly talk to the Jira and Harvest APIs. Additionally we used the scheduling part of Spring Boot to create jobs that will query the time sources for new worklogs and that will store them using Spring Boot Data in a PostgreSQL database. A second job then runs that will make the correct changes on the target systems.
We modelled a small domain in the time sync component that centers around TimeChunks. A TimeChunk is a generic representation of time spent on something which in Jira translates to a worklog. We also added a TimeChunkCorrelation class that will give us enough information to be able to track the link between a TimeChunk in a target system and the same one in the source system. For the hackathon this was done by keeping a record of the IDs used in both systems.
Because of the chosen solution no changes have to be made in the target systems, only Harvest in this case, as we are only interacting with them by using their APIs and so the only thing we need is a valid set of credentials or a token that we can use to call the APIs.
In the end we managed to get most of the system up and running and except for some edge cases it was functional for the Jira to Harvest combination for add/update/delete.

Conclusion
- Timesheets will always suck, but should be made as easy and friendly as possible, even when multiple systems/formats are needed.
- There is no OOTB system that does what we want.
- The Harvest and Jira APIs might not always be the clearest, but everything we needed to be able to access them could be accessed.
- The Element Connect plugin for Jira was a handful to get working correctly for related fields, but worked beautifully in the end.
- Spring Boot is about as low-code as you can get on the Java side for a time limited hackathon like this.
- Following a methodology/plan in a hackathon has its value, as does enough sleep.
PS.: we’re now trialling a new methodology where we don’t log time in Jira anymore, only in Harvest. In order to track project progress, Jira does some magic with cycle time, which should do the trick for our PM’s.