
In our first blog post on CQRS/ES, we briefly explained this architecture pattern, outlined the specific project context in which we found ourselves and also went into the specific reasons that led us to this pattern.
In this blog post, we will go deeper into the technical details and how we applied CQRS/ES in this legacy system.
Chose boring technologies
In 2016 I followed a DDD & CQRS course given by Greg Young and one advice he gave there was: do not use a framework to do CQRS with ES, you can easily set up an ES system yourself with a limited amount of code by using an RDMBS with a batch job that functions as “poor man’s queue”. You can get inspired by the Simple CQRS example project (written in C#) on Greg Young’s GitHub page: https://github.com/gregoryyoung/m-r
When you start with ES it is especially important to focus on the benefits in terms of modelling, the infrastructural set-up is actually less important and you often get very far by consciously choosing “boring” technology, you really do not need new frameworks, or for example Kafka, to do ES.
And that is exactly what we did in our spike to try to event source the most important aggregate in our existing legacy system, this is what it looked like in terms of design:
Architecture overview
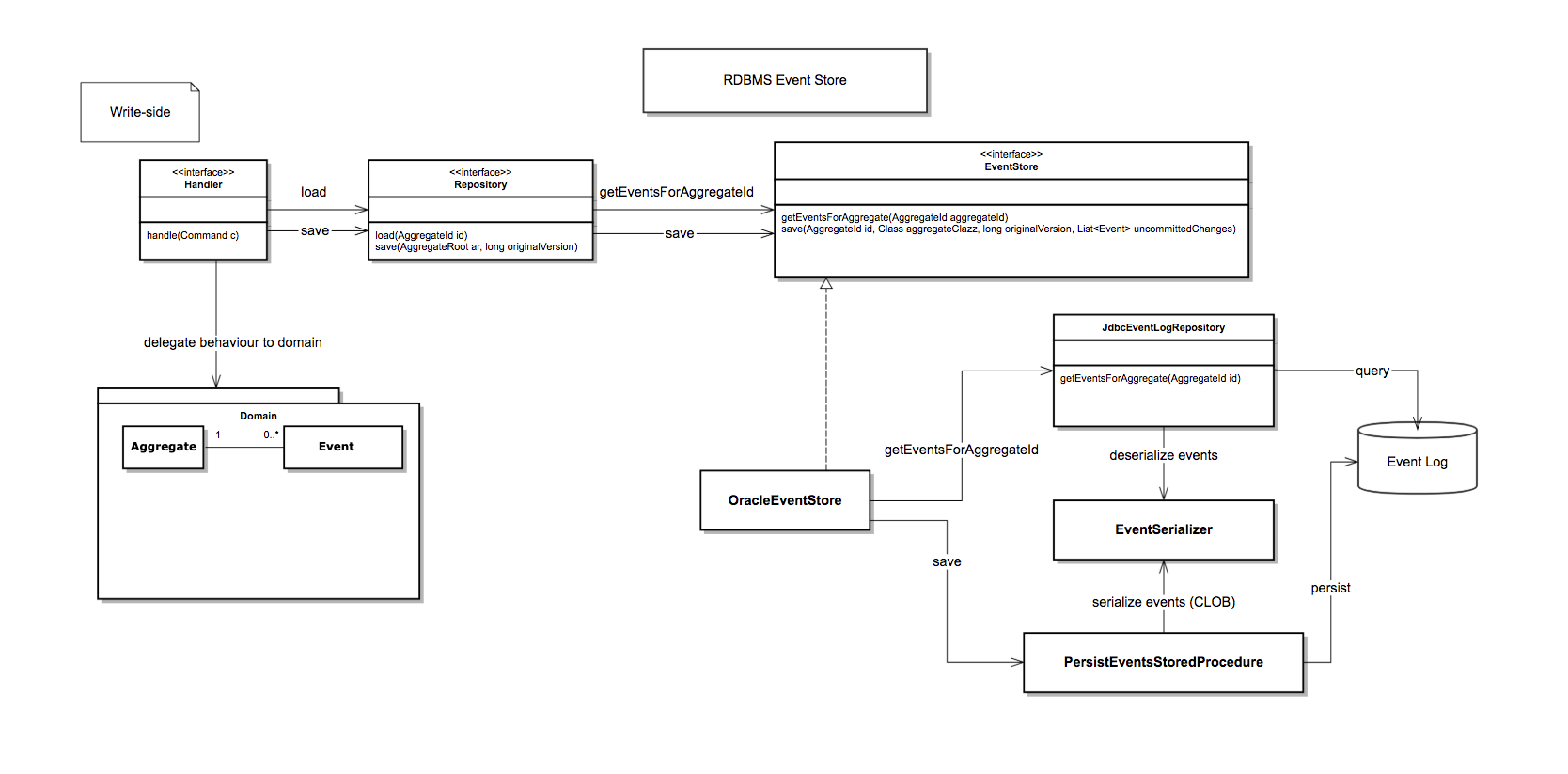
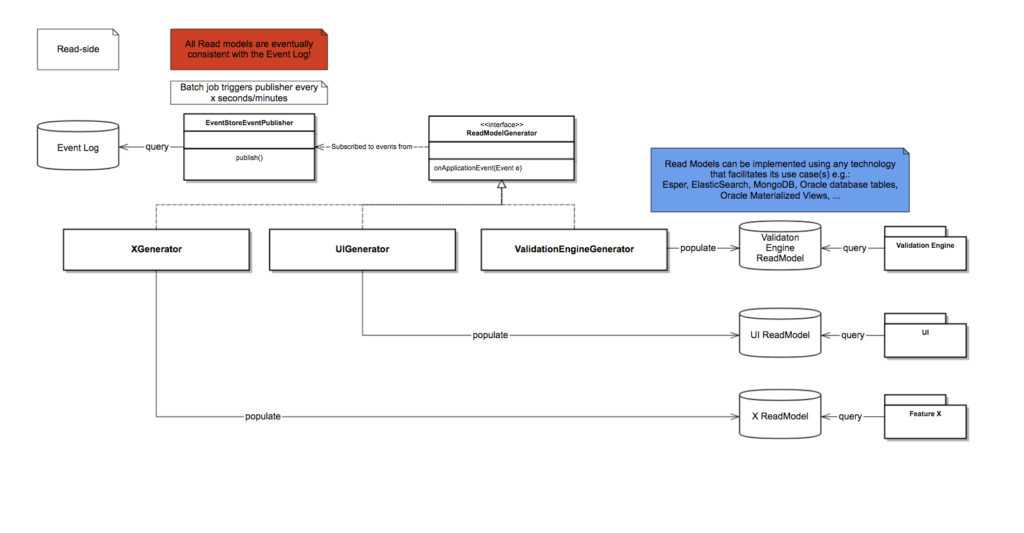
Note that the “PersistentRepository” writes the events as JSON in an Oracle database table, the only mandatory fields that must be in each event are the following:
| Attribute name | Explanation |
|---|---|
| ID (UUID) | Identify an event uniquely, useful for debugging reasons and to build in idempotency on the reading side |
| Version | For optimistic locking, each individual aggregate starts its first event with 0, then 1, etc. (similar to the “version” field in an ORM) |
| Name | The name of the event |
| AggregateID | The specific aggregate to which the event belongs, if the current state of the aggregate has to be rebuilt, all events with the same aggregate id will be replayed in the correct order |
| The specific attributes of the event |
When this spike seemed to be a success and we decided to implement it, one of the most important exercises was to remodel the aggregate, the story of how we tackled that is out of scope for this blog post but I want to repeat here that it is very important you also think very carefully about the events themselves, what domain events should you register, what should they be called (the DDD ubiquitous language!), their attributes etc.
Make sure this is a team effort and that you also involve business analysts and domain experts.
Since we were working in a legacy system we did not use an external queue to publish events but a simple Spring batch job that ran every few seconds and put a configurable number of events in an in-memory queue.
The advantage of doing this was that it was very easy to implement and because the system remained monolithic it did not add all the complexity of a distributed system to the project.
The disadvantage is of course that the system remains monolithic and that this set-up is therefore not very scalable. However, this was not a concern in this project as the scalability of the monolith had not been a problem so far and the scale on which the application should be able to work going forward was well known. No constraint in the context of this specific project but your mileage may vary!
Lessons learned
- The dark side of event sourcing: versioning of events, this is a complex topic, so complex even that Greg Young is writing a whole book about it. One golden tip is to make sure you pay enough attention to modelling events and really consider them as part of the domain model.
- Another trade-off we did not initially foresee: By applying ES you gain flexibility in modelling your domain model. The domain model only exists in memory and you can modify and adjust it relatively easily, without data migrations, because only the events are persistent. But of course, this means that the events themselves are difficult to change!
- Do not underestimate the complexity of CQRS and ES, only use it if necessary and if it fits in the specific context you are in, I also asked Greg Young during the course when he would not use it himself and his answer was clear: if a simple CRUD application will do you can get away with using simple Transaction Scripts and an ORM.
- Not introducing new frameworks to do CQRS/ES was a good choice, you do not need a lot of infrastructure code to build a simple event store on top of an RDMBS with a batch job, this also limits the number of new things you have to learn with your team.
Resources
- Greg Young’s book on versioning in an event sourced system
- Choose boring technology






